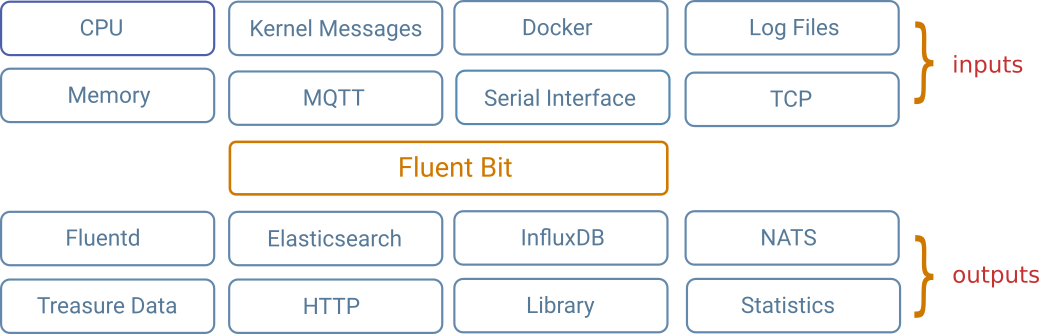
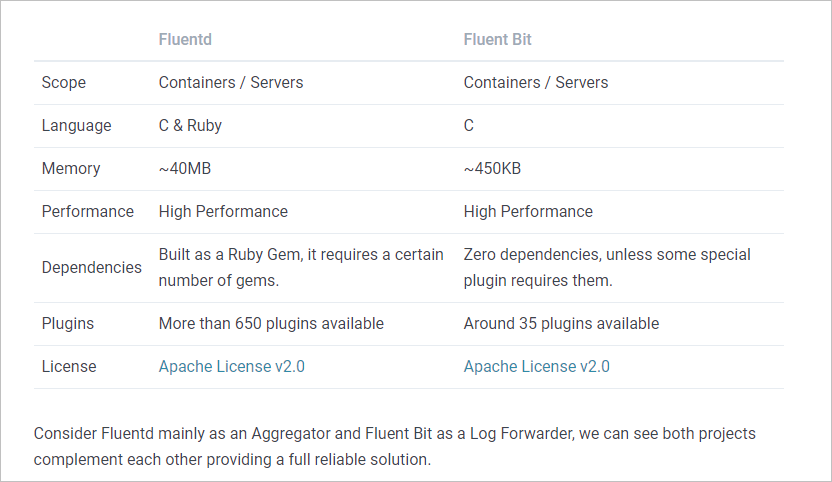
Fluentd is a log collector, processor, and aggregator.
Fluent Bit is a log collector and processor (it doesn’t have strong aggregation features like Fluentd).
安装
Docker
docker pull fluent/fluent-bit:1.3 # run the following (useless) test which makes Fluent Bit measure CPU usage by the container docker run -ti fluent/fluent-bit:1.3 /fluent-bit/bin/fluent-bit -i cpu -o stdout -f 1
# out put Fluent-Bit v1.3.x Copyright (C) Treasure Data
[SERVICE] # Flush # ===== # Set an interval of seconds before to flush records to a destination Flush 5
# Daemon # ====== # Instruct Fluent Bit to run in foreground or background mode. Daemon Off
# Log_Level # ========= # Set the verbosity level of the service, values can be: # # - error # - warning # - info # - debug # - trace # # By default 'info' is set, that means it includes 'error' and 'warning'. Log_Level info
that configuration configure an optional buffering mechanism where it root for data is /var/log/flb-storage/, it will use normal synchronization mode, without checksum and up to a maximum of 5MB of memory when processing backlog data.
[SERVICE] flush 1 log_Level info storage.path /var/log/flb-storage/ storage.sync normal storage.checksum off storage.backlog.mem_limit 5M
# Specify the buffering mechanism to use. It can be memory or filesystem. [INPUT] name cpu storage.type filesystem
[INPUT] name mem storage.type memory
Metrics
By default configured plugins on runtime get an internal name in the format plugin_name.ID. For monitoring purposes this can be confusing if many plugins of the same type were configured. To make a distinction each configured input or output section can get an alias that will be used as the parent name for the metric.
[SERVICE] HTTP_Server On HTTP_Listen 0.0.0.0 HTTP_PORT 2020
[INPUT] Name cpu Alias server1_cpu
[OUTPUT] Name stdout Alias raw_output Match *
# /api/v1/metrics/prometheus
Upstream Servers
It’s common that Fluent Bit output plugins aims to connect to external services to deliver the logs over the network, this is the case of HTTP, Elasticsearch and Forward within others. Being able to connect to one node (host) is normal and enough for more of the use cases, but there are other scenarios where balancing across different nodes is required. The Upstream feature provides such capability.
An Upstream defines a set of nodes that will be targeted by an output plugin, by the nature of the implementation an output plugin must support the Upstream feature. The following plugin(s) have Upstream support: Forward.
The current balancing mode implemented is round-robin.
# The following example defines an Upstream called forward-balancing which aims to be used by Forward output plugin, it register three Nodes: [UPSTREAM] name forward-balancing # node-1: connects to 127.0.0.1:43000 [NODE] name node-1 host 127.0.0.1 port 43000 # node-2: connects to 127.0.0.1:44000 [NODE] name node-2 host 127.0.0.1 port 44000 # node-3: connects to 127.0.0.1:45000 using TLS without verification. It also defines a specific configuration option required by Forward output called shared_key. [NODE] name node-3 host 127.0.0.1 port 45000 tls on tls.verify off shared_key secret
Scheduler
Fluent Bit has an Engine that helps to coordinate the data ingestion from input plugins and call the Scheduler to decide when is time to flush the data through one or multiple output plugins. The Scheduler flush new data every a fixed time of seconds and Schedule retries when asked.
# The following example configure two outputs where the HTTP plugin have an unlimited number of retries and the Elasticsearch plugin have a limit of 5 times: [OUTPUT] Name http Host 192.168.5.6 Port 8080 Retry_Limit False
[OUTPUT] Name es Host 192.168.5.20 Port 9200 Logstash_Format On Retry_Limit 5
Input Plugins Tail
The plugin reads every matched file in the Path pattern and for every new line found (separated by a \n), it generates a new record. Optionally a database file can be used so the plugin can have a history of tracked files and a state of offsets, this is very useful to resume a state if the service is restarted.
[INPUT] Name tail Path /var/log/syslog
[OUTPUT] Name stdout Match *
Parser
By default, Fluent Bit provides a set of pre-configured parsers that can be used for different use cases such as logs from: Apache, Nginx, Docker, Syslog rfc5424, Syslog rfc3164.
All parsers must be defined in a parsers.conf file, not in the Fluent Bit global configuration file. The parsers file expose all parsers available that can be used by the Input plugins that are aware of this feature. A parsers file can have multiple entries like this:
[PARSER] Name docker Format json Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On
[PARSER] Name syslog-rfc5424 Format regex Regex ^\<(?<pri>[0-9]{1,5})\>1 (?<time>[^ ]+) (?<host>[^ ]+) (?<ident>[^ ]+) (?<pid>[-0-9]+) (?<msgid>[^ ]+) (?<extradata>(\[(.*)\]|-)) (?<message>.+)$ Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On Types pid:integer
Remove_wildcard Mem Remove_wildcard Swap Add cpustats_more STILL_UNKNOWN
[OUTPUT] Name stdout Match *
Routing
There are two important concepts in Routing: Tag, Match
When the data is generated by the input plugins, it comes with a Tag (most of the time the Tag is configured manually), the Tag is a human-readable indicator that helps to identify the data source.
In order to define where the data should be routed, a Match rule must be specified in the output configuration.
# Consider the following configuration example that aims to deliver CPU metrics to an Elasticsearch database and Memory metrics to the standard output interface: [INPUT] Name cpu Tag my_cpu
[INPUT] Name mem Tag my_mem
[OUTPUT] Name es Match my_cpu
[OUTPUT] Name stdout Match my_mem
Routing works automatically reading the Input Tags and the Output Match rules. If some data has a Tag that doesn’t match upon routing time, the data is deleted.
Routing with Wildcard: Routing is flexible enough to support wildcard in the Match pattern. The below example defines a common destination for both sources of data:
# The match rule is set to my_* which means it will match any Tag that starts with my_. [INPUT] Name cpu Tag my_cpu
[INPUT] Name mem Tag my_mem
[OUTPUT] Name stdout Match my_*
Output Plugins
Elasticsearch
[INPUT] Name cpu Tag cpu
[OUTPUT] Name es Match * Host 192.168.2.3 Port 9200 Index my_index Type my_type